正文
今天要來紀錄的是dplyr的操縱函式,先針對提取案例(Extract Cases)進行練習,以下函式會回傳一組資料列作為新的資料表:
1. ==
2. <
3. <=
4. is.na()
5. %in%
6. |
7. xor()
8. !=
9. >
10. >=
11. !is.na()
12. !
13. &
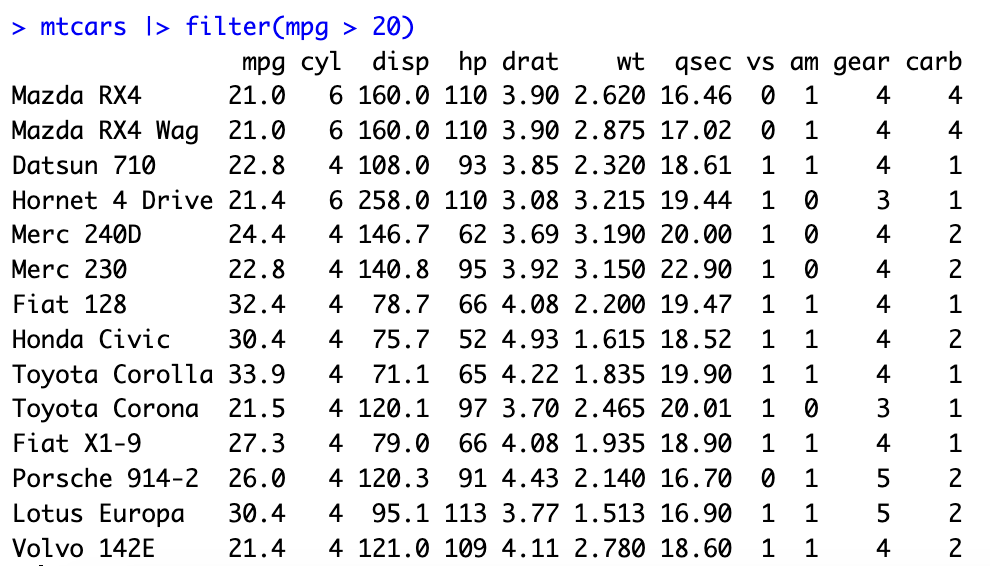
篩選mtcars資料集中mpg大於20的資料列
mtcars |> filter(mpg > 20)
取出mtcars資料集的gear不重複資料列
mtcars |> distinct(gear)

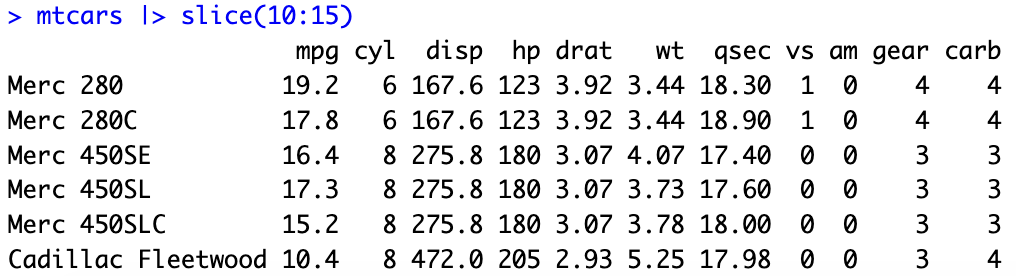
取出mtcars資料集的第10列到第15列
mtcars |> slice(10:15)
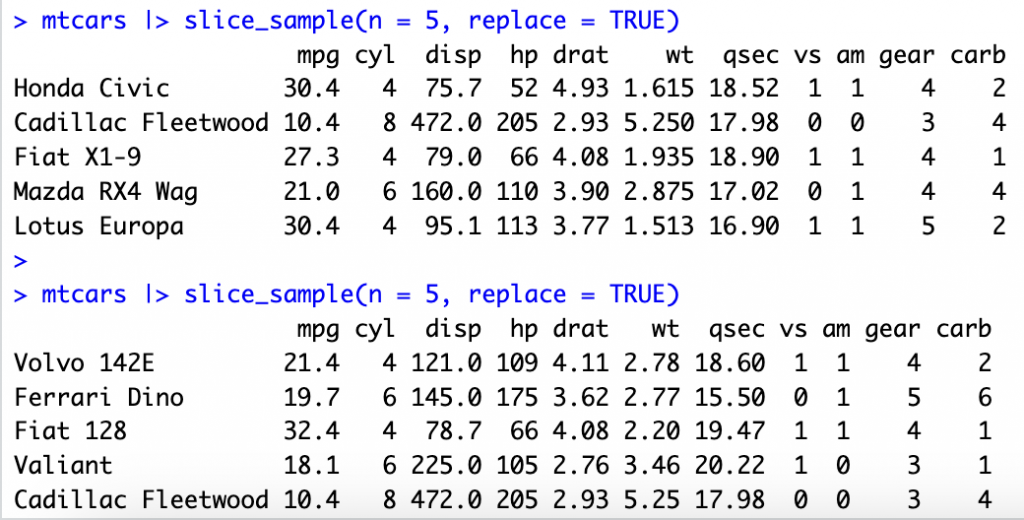
隨機取出mtcars資料表5個資料列
mtcars |> slice_sample(n = 5, replace = TRUE)
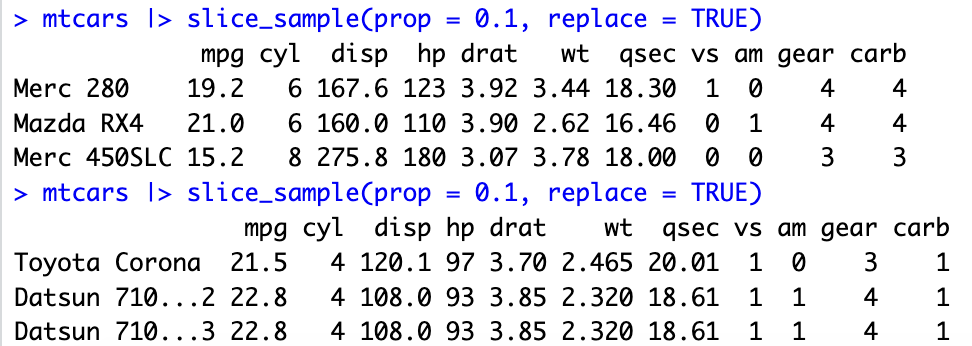
隨機取出mtcars資料表10%比例數量的資料列
mtcars |> slice_sample(prop = 0.1, replace = TRUE)
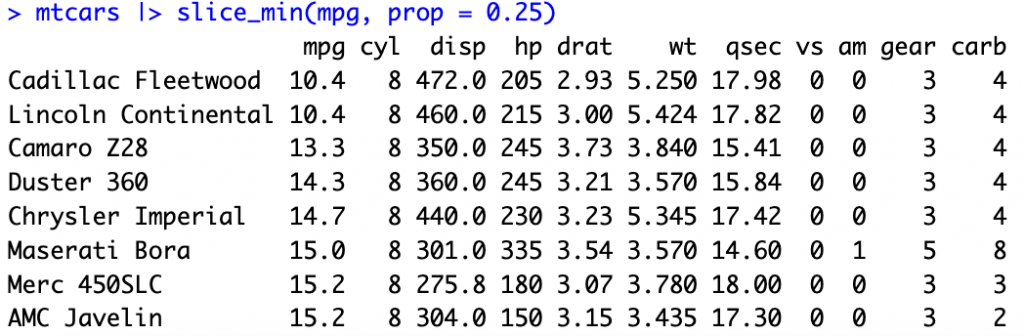
取mtcars資料集mpg前25%數量最小的資料列
mtcars |> slice_min(mpg, prop = 0.25)
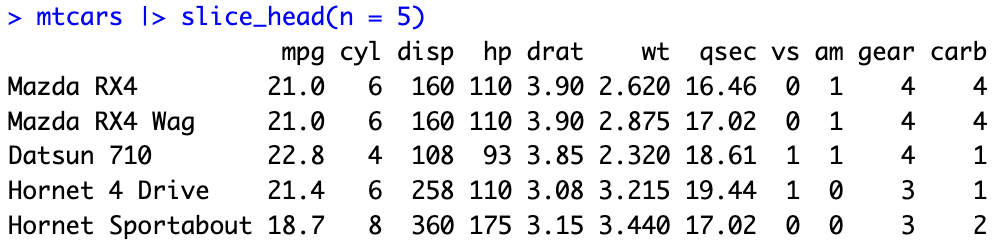
取mtcars資料集前5列的資料列
mtcars |> slice_head(n = 5)
今天的小筆記就先到這邊,大家明天見~~
參考資料:Data transformation with dplyr :: Cheatsheet

